0. 前言#
在 NLP 中, 经常可以看到使用”困惑度”来描述一个 LLM 的能力. 那么什么是”困惑度”?
简单理解, 困惑度就是”模型对样本预测结果的信心”. 具体的, 模型对这个样本结果的预测概率越高, 表明信心越高, 对应困惑度越低.
NOTE本文介绍的Perplexity 特指 “Perplexity of a probability model”.
1. 举个栗子#
假设我们的 vocabulary 就只有6个单词, “a”, “the”, “red”, “fox”, “dog”, and “.” . 模型需要从这里边预测输出句子 W : "a red fox ."
P(W)=P(w1,w2,…,wn)=P(wn∣w1,w2,…,wn−1)×P(w1,w2,…,wn−1)对于这句话就是:
P(′a red fox .′)=P(′a′)×P(′red′∣′a′)×P(′fox′∣′a red′)×P(′.′∣′a red fox′)假设模型, 预测第一个字的概率分布如下 :
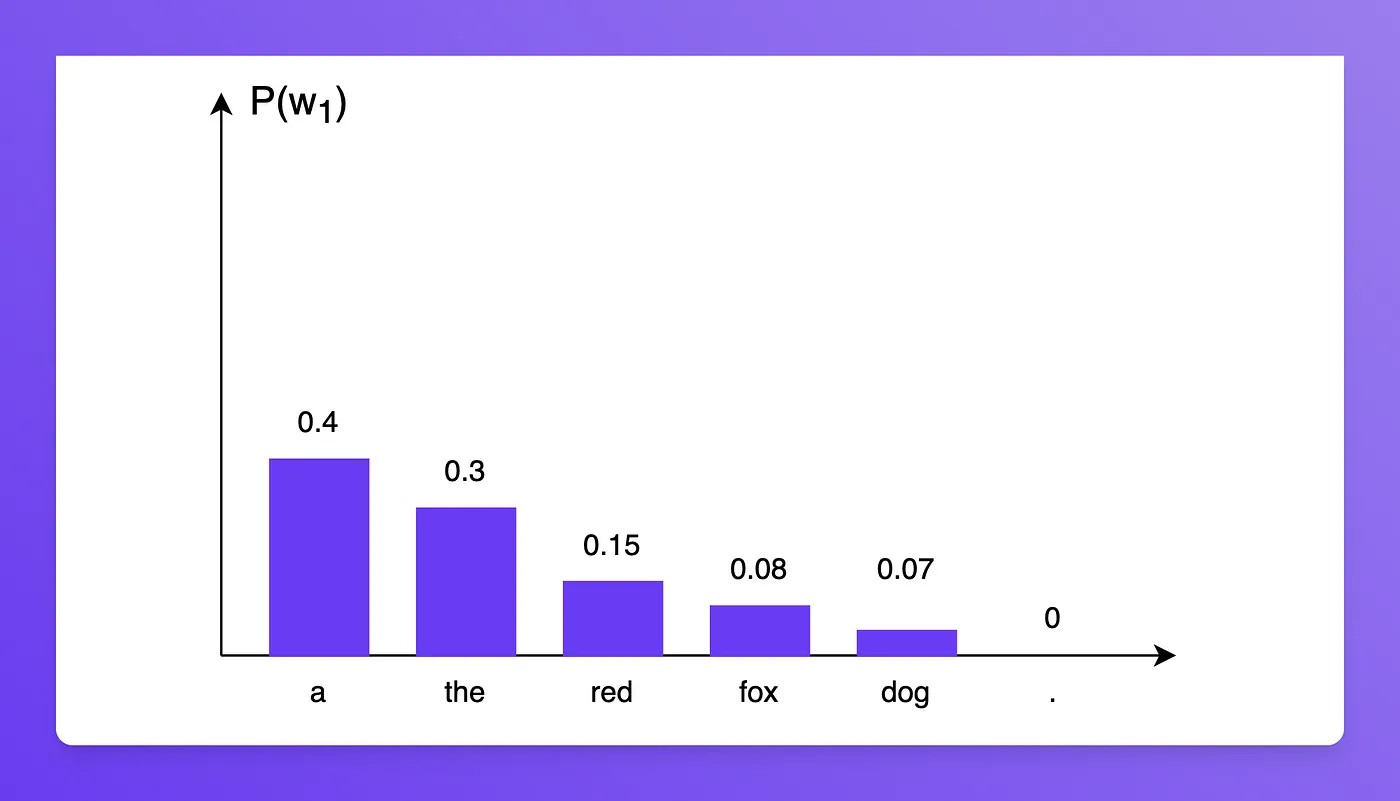
则有
P(′a′)=0.4
, 进一步的
P(w2∣′a′)
分布如下
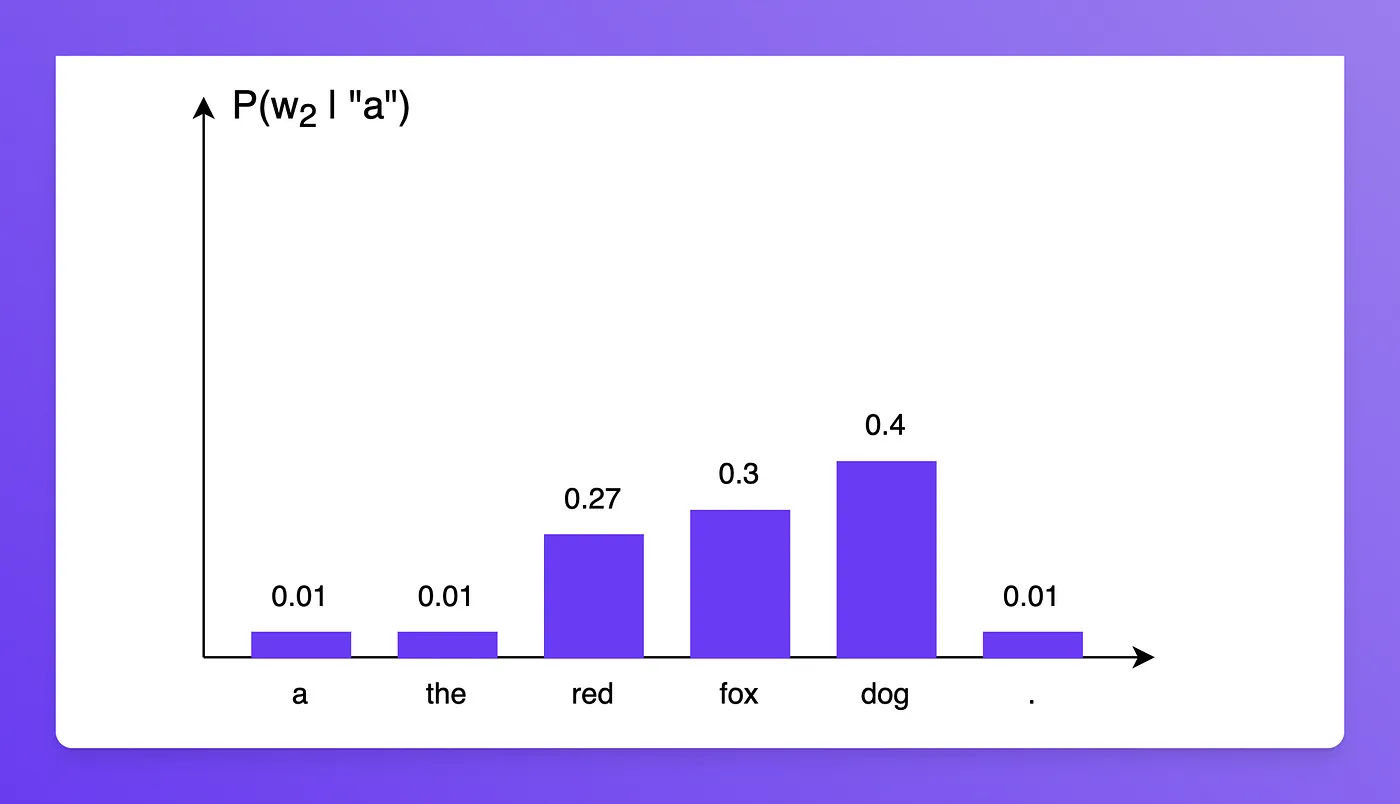
于是
P(′red′∣′a′)=0.27
, 同理, 根据以下分布
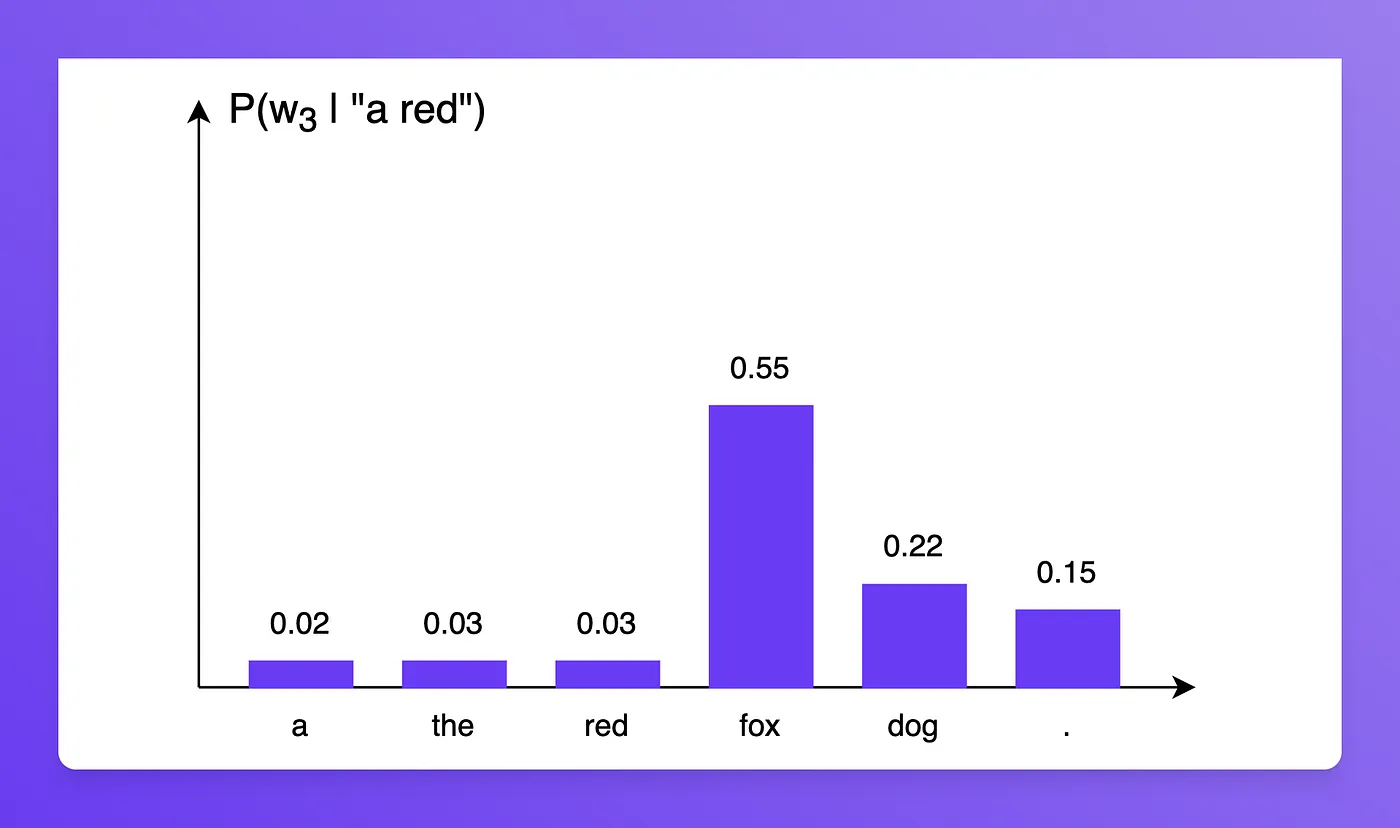
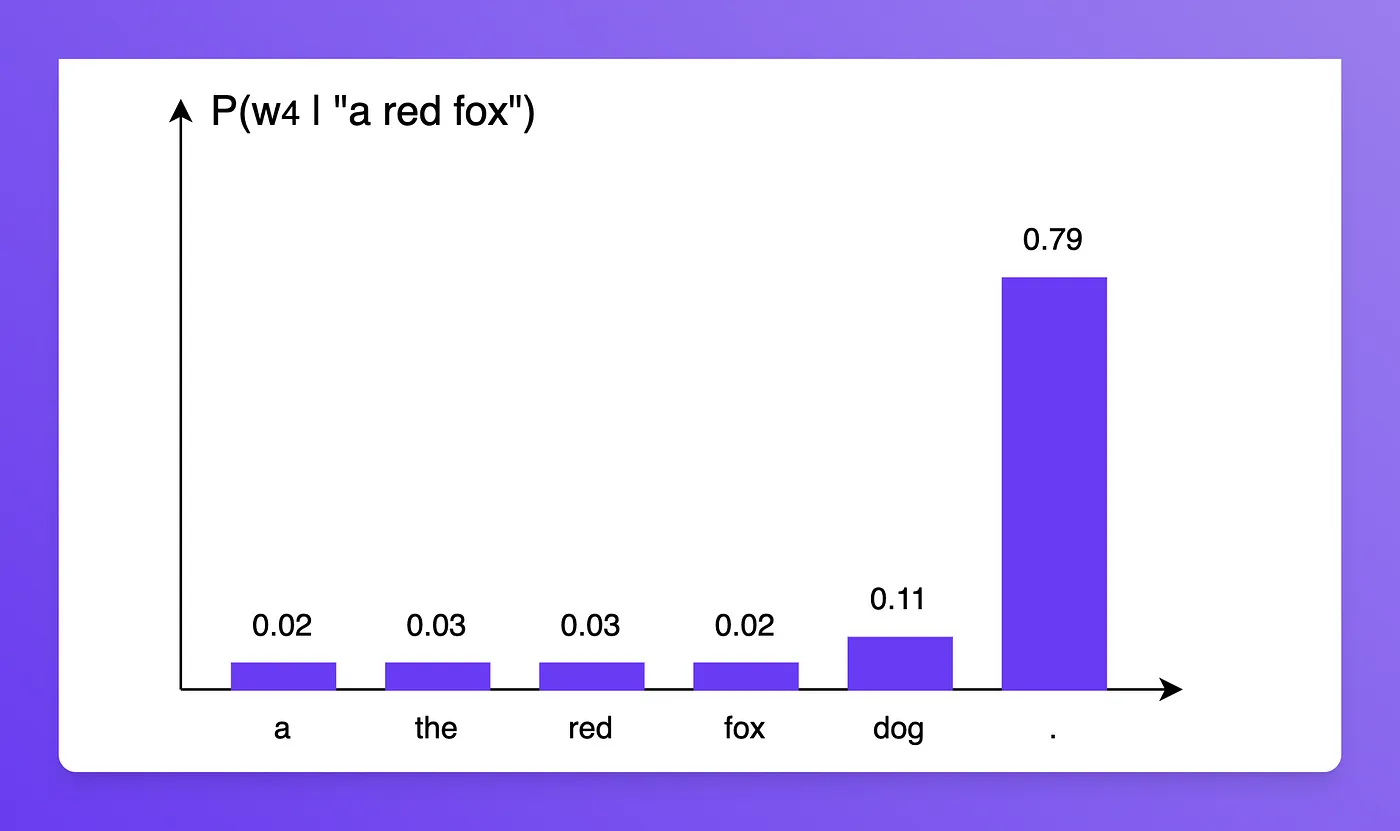
我们有如下结果:
P(′a red fox .′)=P(′a′)×P(′red′∣′a′)×P(′fox′∣′a red′)×P(′.′∣′a red fox′)=0.4∗0.27∗0.55∗0.79=0.04690.0469则表示当前这个模型对于预测 “a red fox.” 的信心如何, 不过有一个问题 : 因为这个信心是概率的连乘, 于是导致理论上, 句子越长, 信心越小. 因此需要进行一个 “Normalize”的操作 . 我们可以使用 几何平均数 来实现上述功能, 从而得到一个新的量化标准:
Pnorm(W)=P(W)1/n这里的n表示句子的单词(token)数量.于是
Pnorm(′a red fox .′)=P(′a red fox .′)1/n=0.04691/4=0.465这样我们就可以使用 Pnorm 来度量模型对不同长度句子的预测输出”信心”.
2. 如何计算#
前边我们提到, 模型与输出的句子, 信心越足, 困惑度越小. 可以看到, 困惑度的计算公式如下:
PP(W)=Pnorm(W)1=P(W)1/n1=(P(W)1)1/n=P(W)−1/n对于之前的这个模型, 其 PP(W)=(1/0.0469)1/n≈2.15
而假设有另外一个模型, 给定任意条件下, 对下一个单词的预测概率均相等为 1/6 . 那么这个模型的的困惑度为:
PP(W)=((1/6)41)1/4=6
明显比之前的模型困惑度更高, 表明这个模型 更差 , 因为这个模型就是随机输出.
3. 和交叉熵的关系#
我们知道, 香农熵 计算方式为 :
H(p)=−i=1∑nplog2p交叉熵的计算方式:
H(p,q)=−i=1∑nplog2q
事实上:
KL(p,q)=−H(p)+H(p,q)
对PP(W)进行拆解, 得以下式子:
(1) 注意之前是 n , 强调一个句子. 这里是 N , 强调模型对整个vocabulary的输出分布
(2) 最后的 q分布 就是下一个单词的分布, 是一个 One-hot 向量
P(W)−1/N=i=1∏NP(w)−1/N=P(w1)−1/N∗P(w2)−1/N∗...∗P(wN)−1/N=2−N1 ∑i=1N log2 p(忽略常数2−1/N)=2 H(P, q)从这个角度来看, 困惑度越小, 交叉熵越小, 预测越准确.
最后, 实际计算过程中, 可能使用以e为底的对数, 也有计算其log后作为困惑度, 此外还有一些其他计算方式, 但是本质类似, 就是想表达 “预测输出的概率越大, 困惑度就越小”