设 X 是一个随机变量,其分布函数f(x), 累积分布函数 (CDF, Cumulative distribution function) 为 F(x) , 该函数是一个单调递增的函数, 其值域为[ 0 , 1 ]. 现在定义一个新的随机变量Y=F(X) , 则 随机变量 Y 的分布是均匀分布.
1.1 逆变换采样法#
设 X 是一个随机变量,其分布函数f(x), 累积分布函数 (CDF, Cumulative distribution function) 为 F(x). 则依据如下采样过程, 得到的x是服从分布f(x)的.
- 从均匀分布 U(0, 1) 中生成一个随机数 u
- 计算 F(x) = u 的解 x
- 输出 x 作为采样结果
根据引理1容易知道, 如果从均匀分布 U(0,1) 中生成一个随机数 u,并令 x=F−1(u),则 x 服从原分布F(x)。(理解为本身这个F就是我们想采样的 f 对应的 F, 那反函数求解出来的 x 自然就是 满足 f(x) 和 F(x) ) , 即为 逆变换方法 , 几个具体实现: https://lwz322.github.io/2019/06/02/ITM.html
1.2 拒绝采样法#
-
准备工作
- 已知 概率密度函数f(y), 我们需要依据这个分布进行抽样
- 找一个任意能够直接进行采样的分布g(y) (比如均匀分布)
- 找一个常数 c, 满足对 ∀y , 均有 c×g(y)>=f(y), 即 c 是函数 g(y)f(y) 的上界 或者 c×g(y) 能够覆盖 f(y)
-
抽样流程
- 从 g(y) 中中随机采样一个样本 yi
- 从均匀分布 U(0,1) 中采样一个随机数 ui
- 如果 ui<=c∗g(yi)f(yi) 成立, 则保留该样本 yi, 否则返回 step1重复. 可以证明, 这样从 g(y) 抽出的样本 yi 是满足概率密度函数 f(y) 及其对应的CDF函数
-
证明
证明上述采样方法生成的样本服从 f(y) , 等价于证明以下内容
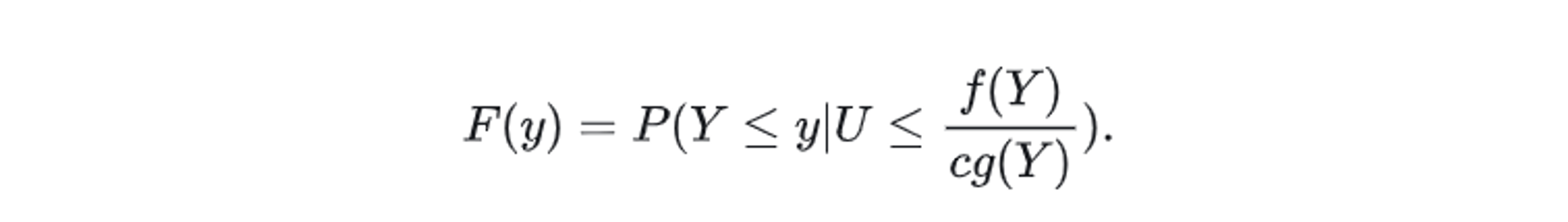
其中 , U 为 [0,1] 的随机数, y 是从 g(y) 采样得到的 , F 和 G 分别是 f 和 g 对应的累积分布函数.
根据贝叶斯公式
P(A∣B)=P(B)P(B∣A)P(A)
将 P(Y<=y∣U<=c∗g(Y)f(Y)) 用贝叶斯公式转化为:
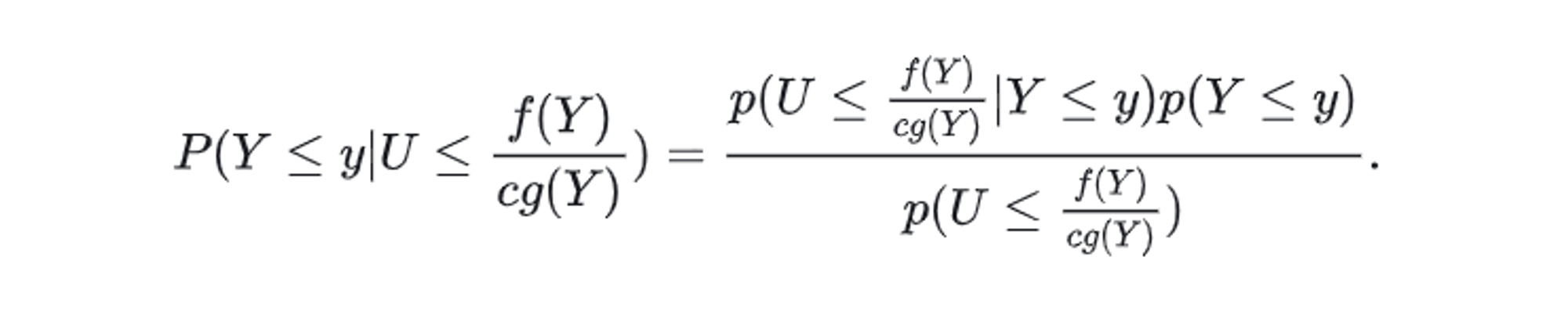
现在分别来看 右边的 3个式子
(1) 分母
P(U<=c∗g(Y)f(Y))=∫P(U<=c∗g(Y)f(Y)∣Y=y)p(Y=y)
由于 y 是从 g 中抽样得到的 , 那么 p(Y=y)=g(y) , 不妨假设此时 y 的抽样结果 : Y=y , 又因为 U 是均匀的 0 , 1 分布 , 按定义 我们有
P(U<=c∗g(Y)f(Y)∣Y=y)=c∗g(y)f(y)
此外, 由于∫f(y)=1 , 我们有
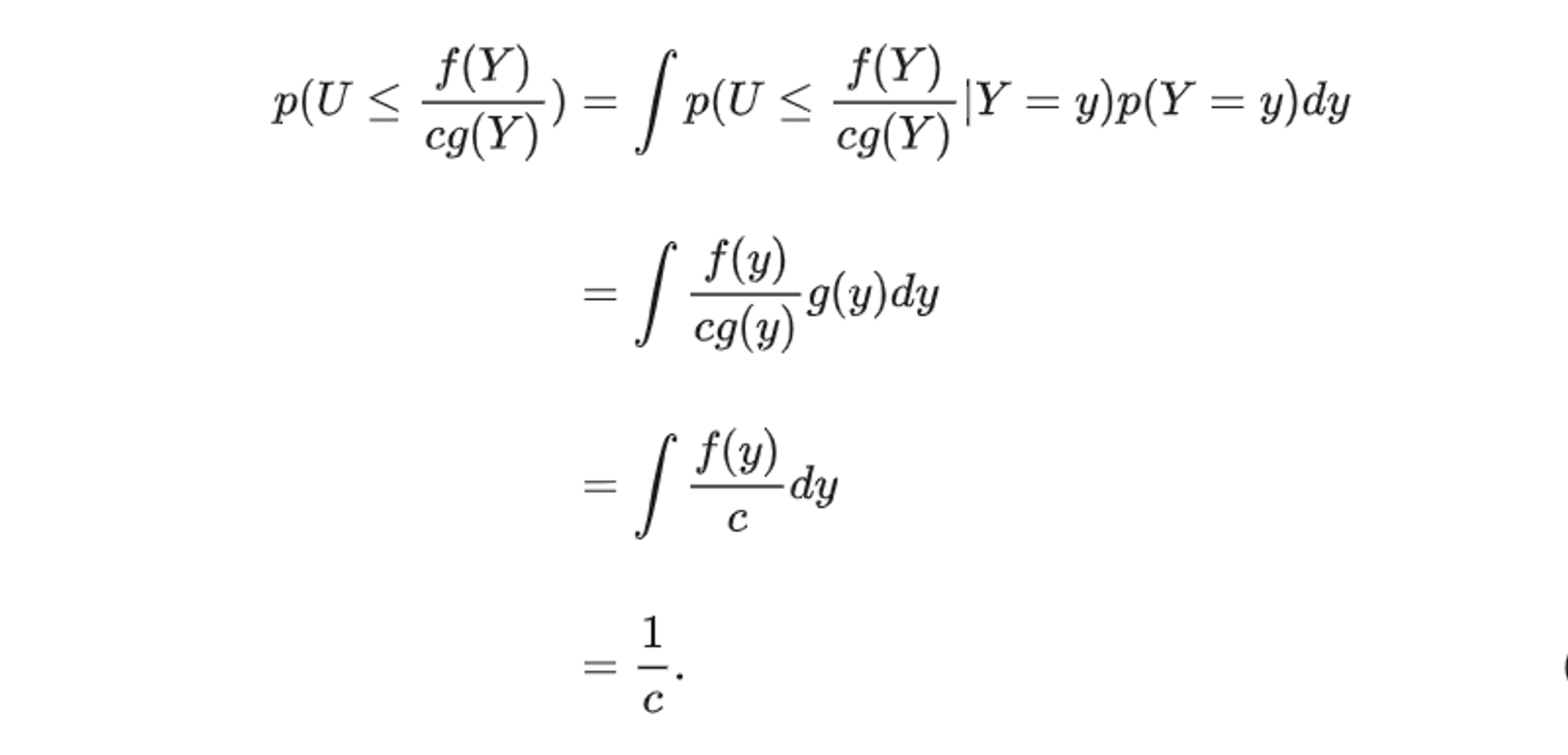
(2) 分子 p(Y<=y)
按照定义
p(Y<=y)=G(y)
(3) 分子 P(U<=c∗g(Y)f(Y) Y<=y)
P(U<=c∗g(Y)f(Y)∣Y<=y)=P(Y<=y)P(U<=c∗g(Y)f(Y),Y<=y)=G(y)∫−∞yP(U<=c∗g(w)f(w),Y=w<=y) dw=G(y)∫−∞yc∗g(w)f(w)∗g(w) dw=G(y)c∗G(y)F(y)∗G(y)=c∗G(y)F(y)
于是, 原始公式可进行转化, 从而证明完毕:
P(Y<=y∣U<=c∗g(Y)f(Y))=c1c∗G(y)F(y)∗G(y)=F(y)假设复杂分布 P(z) , 存在常数 k 与 任意分布 q(z) , 以 z0 点为例, 画直线, 任意从均匀分布抽取一个点 ui, 可以理解为在 x=z0 这条直线上取一点: 就是 ui∗k∗q(z0), 其处于阴影即拒绝 (即 U∗k∗q(z0)>p(z0)) , 处于白色区域即接受( U∗k∗q(z0)<=p(z0) ) , 这样从 z0 出来的点对应的最大概率就是f(z0) , 等价于是从 f(x) 抽样出来的
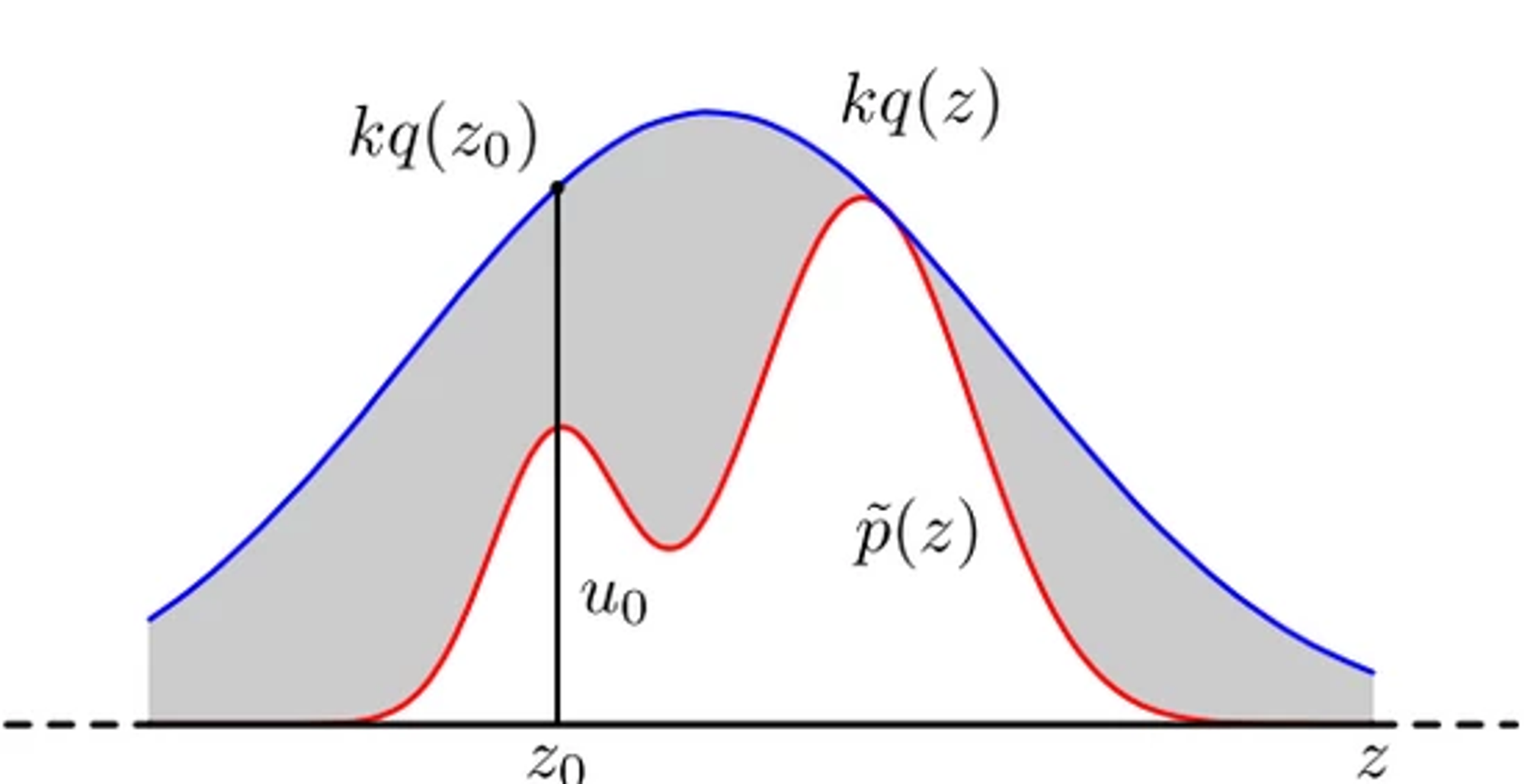
上述2个方法都属于Monte-Carlo 方法, 并且是已知 P(θ) 的情况下 , 然后在某些特殊场景下, 已知了 参数的后验分布 和 先验分布 的关系(比如之前提到的共轭) , 才能得到一个比较简易的形式 , 直接对后验分布更新. (当我们面临无法得到具体形式的非共轭后验分布时,我们无法采用这种算法。)
然而, 面对一些复杂的分布, 即使我们已知了 P(θ) , 再利用贝叶斯公式的时候 , 其分母涉及到积分, 往往也是很难求解的
P(θ∣X)=∫P(X∣θ)P(θ)dθP(X∣θ)P(θ)上述提到分母有时候很难进行积分,对于这个问题,一个直观的想法就是 ,能不能通过某个手段把 分母去掉?
P(θa∣X)=P(X)P(X∣θa)P(θa)P(θb∣X)=P(X)P(X∣θb)P(θb)二者做比值
γ=P(θb∣X)P(θa∣X)=P(X∣θb)P(θb)P(X∣θa)P(θa)这样避免了分母的积分,这里 P(θa) 可以参考 Dirichlet Distribution (多维)或者 Beta Distribution (二维). 思想是这样的, 不过需要一点点其他知识.
NOTE未完待续…