0. 前言#
在正式推导之前, 我们先想清楚一件事: 我们到底希望位置编码做到什么?
回忆一下, Transformer 的 Self-Attention 计算的是 query 和 key 的内积:
score=qTk问题是这个分数跟位置完全无关。把词序打乱, attention 输出一样。
所以我们需要给每个位置上的 query 和 key 加上位置信息, 让 attention 能感知到”谁在哪儿”。
但”加上位置信息”这个说法太笼统了。更精确地说, 我们希望:
编码位置后, 两个 token 的 attention score 只依赖于它们的相对位置差, 而不依赖于它们各自的绝对位置。
这是整篇文章推导的起点。搞清楚了这一点, 后面的所有公式就有了方向。
1. 设定目标#
把位置编码表示成两个函数:
- fq(q,m): 对位置 m 处的 query 向量 q 进行位置编码
- fk(k,n): 对位置 n 处的 key 向量 k 进行位置编码
我们期望:
⟨fq(q,m),fk(k,n)⟩=g(q,k,m−n)即: 编码后的内积, 只跟词本身(q, k)和相对位置(m−n)有关, 跟绝对位置 m, n 无关.
这就是 RoPE 的推导起点. 接下来我们要做的事是: 什么样的 fq, fk 才能满足这个条件?
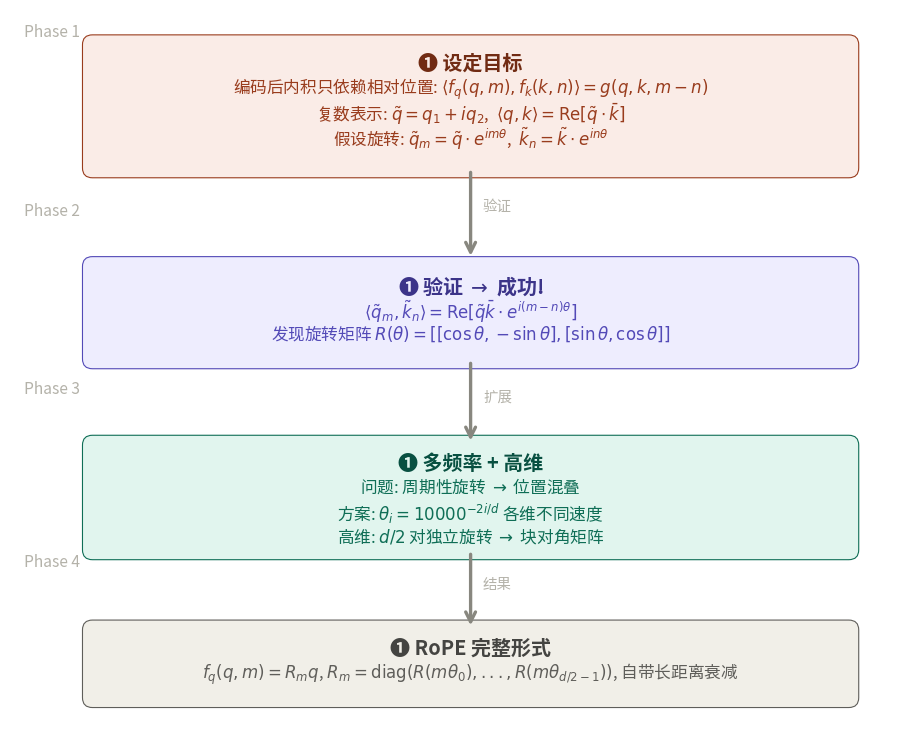
上图为 RoPE 的完整推导路线图. 从目标出发, 通过复数/三角函数, 最终推出旋转矩阵.
2. 从最简单的 2 维情况开始#
为了找到 fq 和 fk 的形式, 我们先考虑最简单的情况: q 和 k 是 2 维向量.
2.1 用复数表示 2D 向量#
2 维向量可以用复数表示:
q=(q1,q2)⟶q~=q1+iq2k=(k1,k2)⟶k~=k1+ik2复数的好处是: 旋转和缩放可以简洁地用乘法表示.
2.2 一个关键的观察#
在复数域中, 两个复数的”内积”(取实部)可以写成:
⟨q,k⟩=Re[q~⋅k~]其中 k~=k1−ik2 是共轭复数.
验证: q~⋅k~=(q1+iq2)(k1−ik2)=(q1k1+q2k2)+i(q2k1−q1k2), 取实部正好是 qTk.
2.3 假设一个形式, 然后验证#
有了这个工具, 我们来假设一种编码方式:
假如我们在复数域上给向量乘以一个单位模长的复数因子来编码位置.
也就是说, 对位置 m 处的向量 q~, 我们给它在复数域上转一个角度:
q~m=q~⋅eimθ同理:
k~n=k~⋅einθ其中 θ 是一个预置的角度参数.
现在来验证这个假设是否满足我们的目标(内积只依赖相对位置):
⟨q~m,k~n⟩=Re[q~m⋅k~n]=Re[q~eimθ⋅k~e−inθ]=Re[q~k~⋅ei(m−n)θ]结果只依赖于 (m−n)! 完美满足目标.
2.4 从复数回到实数矩阵#
现在把复数形式翻译回实数向量和矩阵.
利用欧拉公式 eimtheta=cosmtheta+isinmtheta, 展开复数乘法:
q1′+iq2′=(q1cosmθ−q2sinmθ)+i(q1sinmθ+q2cosmθ)写成矩阵形式就是:
(q1′q2′)=(cosmθsinmθ−sinmθcosmθ)(q1q2)中间这个矩阵——就是旋转矩阵 R(mθ).
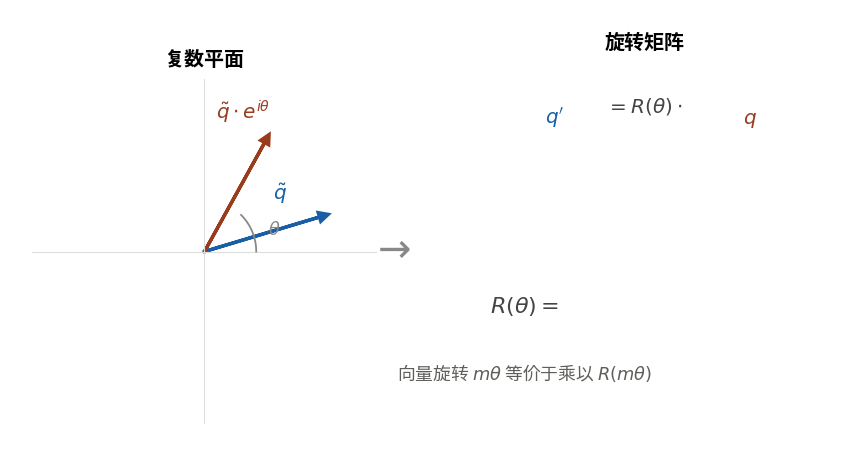
图中展示了复数平面上的旋转如何对应到实数平面的旋转矩阵. 向量旋转 mθ 等价于乘以旋转矩阵 R(mθ).
所以:
fq(q,m)=R(mθ)⋅q,fk(k,n)=R(nθ)⋅k推导的关键: 不是凭空定义了旋转矩阵, 而是从”内积只依赖相对位置”这个目标出发, 通过复数域的自然假设, 反推出了旋转矩阵的形式.
3. 验证: 旋转矩阵形式的内积#
有了旋转矩阵, 我们反过来验证一下内积.
在验证之前, 先确认旋转矩阵的两个重要性质:
性质 1: R(θ) 是正交矩阵, 且 R(θ)T=R(−θ)
R(θ)=(cosθsinθ−sinθcosθ),R(θ)T=(cosθ−sinθsinθcosθ)验算 R(θ)TR(θ):
R(θ)TR(θ)=(cos2θ+sin2θ−sinθcosθ+cosθsinθ−cosθsinθ+sinθcosθsin2θ+cos2θ)=(1001)=I同时 R(−θ)=(cos(−θ)sin(−θ)−sin(−θ)cos(−θ))=(cosθ−sinθsinθcosθ)=R(θ)T, 所以 R(θ)T=R(−θ)=R(θ)−1.
性质 2: R(α)R(β)=R(α+β) (旋转可加性)
把两个旋转矩阵相乘:
R(α)R(β)=(cosαsinα−sinαcosα)(cosβsinβ−sinβcosβ)=(cosαcosβ−sinαsinβsinαcosβ+cosαsinβ−cosαsinβ−sinαcosβ−sinαsinβ+cosαcosβ)=(cos(α+β)sin(α+β)−sin(α+β)cos(α+β))=R(α+β)第二步用了三角函数的和角公式: cos(α+β)=cosαcosβ−sinαsinβ, sin(α+β)=sinαcosβ+cosαsinβ.
好, 有了这两条性质, 验证内积就很简单了. 不过先直观感受一下 RoPE 是怎么工作的:
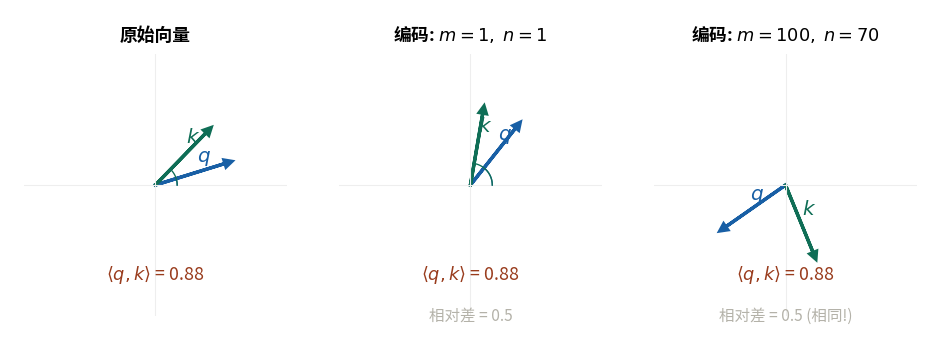
左图: 原始向量 q 和 k. 中图: q 旋转 45°(编码位置 m=1), k 旋转 15°(编码位置 n=1). 右图: 同样两个向量, 但绝对位置更大(m=100, n=70), 因为相对差相同(都是 30°), 所以内积不变. 这就是”只依赖相对位置”的直观体现.
现在用数学验证:
⟨fq(q,m),fk(k,n)⟩=(R(mθ)q)T(R(nθ)k)=qTR(mθ)TR(nθ)k=qTR(−mθ)R(nθ)k(旋转矩阵正交: RT=R−1=R(−θ))=qTR((n−m)θ)k(旋转矩阵可加: R(α)R(β)=R(α+β))=qTR(−(m−n)θ)k展开 R(−(m−n)θ):
R(−(m−n)θ)=(cos(m−n)θ−sin(m−n)θsin(m−n)θcos(m−n)θ)最后的结果只跟 m−n 有关, 验证通过.
4. 为什么需要不同频率#
假设我们只有一个固定频率 θ.
对于位置 m 和 m+1, 旋转角度分别是 mθ 和 (m+1)θ, 差值是 θ. 但问题在于: 当 m 很大时会发生什么?
来看一个具体例子. 假设 θ=0.1, 那么:
- 位置 0: 旋转 0∘, 向量不变
- 位置 1: 旋转 5.7∘
- …
- 位置 30: 旋转 171.9∘
- 位置 31: 旋转 177.6∘
- 位置 63: 旋转 361.0∘ — 转了一整圈多!
R(63×0.1)=R(6.3)≈R(6.3−2π)=R(0.02), 所以 m=63 和 m=0 几乎有相同的旋转矩阵. 位置 63 和位置 0 在 attention 计算中无法区分!
也就是说, 由于 sin 和 cos 是周期函数, 旋转超过一周后, 位置信息就混叠了. 如果词序列很长, 后面的位置会周期性地”穿越”回前面.
所以我们需要多个频率, 让不同的维度对以不同的速度旋转:
- 低维度: 旋转速度快 (θi 大), 能区分精细位置
- 高维度: 旋转速度慢 (θi 小), 能感知大范围距离
频率设置和 Sinusoidal PE 一样:
θi=10000−2i/d,i=0,1,...,d/2−1这个公式的效果是: i 越小, θi 越大(旋转越快), 反之亦然.
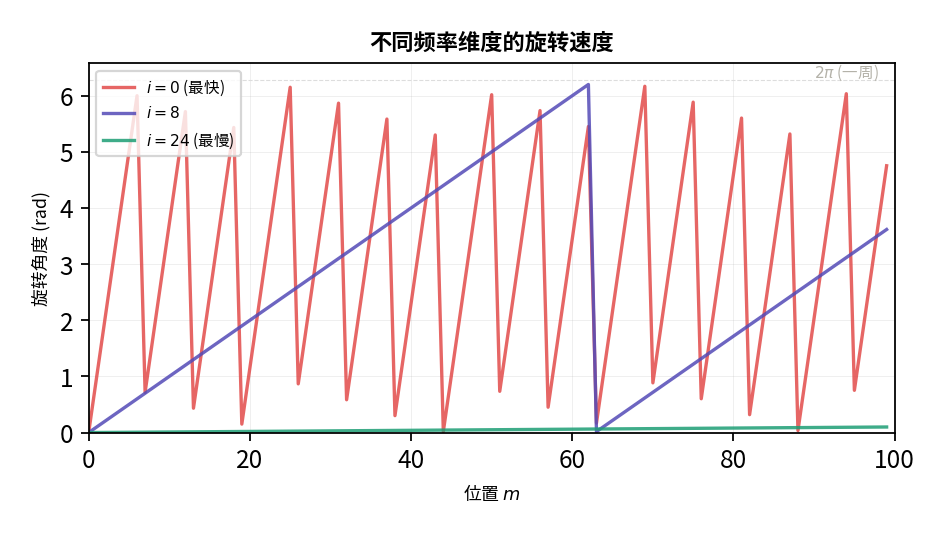
图中展示了三个不同频率的旋转速度. 红色转得最快(低维度), 蓝色次之, 绿色最慢(高维度).
5. 从 2D 扩展到高维#
既然 2D 情况下的位置编码是旋转, 那高维呢?
答案很自然: 把向量切成 d/2 对, 每对独立旋转.
对于 8 维向量, 它的旋转矩阵是一个分块对角矩阵:
Rm=R(mθ0)0000R(mθ1)0000R(mθ2)0000R(mθ3)其中每个 R(mθi) 是 2×2 的旋转矩阵.
这个分块矩阵作用于 8 维向量时, 第 1-2 维用 θ0, 第 3-4 维用 θ1, 以此类推. 每对维度独立旋转, 互不干扰.
写成公式就是:
fq(q,m)(2i,2i+1)=(q2icosmθi−q2i+1sinmθiq2isinmθi+q2i+1cosmθi)为什么可以这样做? 这里需要一点简单的推导。
假设我们把 d 维向量 q 切分成 d/2 个 2 维子向量 q(0),q(1),...,q(d/2−1), 其中 q(i)=(q2i,q2i+1). 那么内积可以写成:
⟨q,k⟩=j=1∑dqjkj=i=0∑d/2−1(q2ik2i+q2i+1k2i+1)=i=0∑d/2−1⟨q(i),k(i)⟩这个式子成立, 仅仅是因为内积的定义就是对应位置相乘再求和, 我们可以自由地按任何顺序分组求和——交换律和结合律而已. 这个证明不需要任何额外的数学知识, 就是最基础的向量内积定义.
现在, 如果我们对每个子向量 q(i) 独立施加旋转 R(mθi), 那么编码后的内积就是:
⟨fq(q,m),fk(k,n)⟩=i=0∑d/2−1⟨R(mθi)q(i),R(nθi)k(i)⟩我们在 2D 情况下已经证明过, 每个子空间的内积都只依赖于 m−n:
⟨R(mθi)q(i),R(nθi)k(i)⟩=⟨q(i),R((n−m)θi)k(i)⟩所以整个内积也只依赖 m−n. 证毕.
这样我们就实现了 d 维向量到 d/2 个独立 2D 旋转的分解.
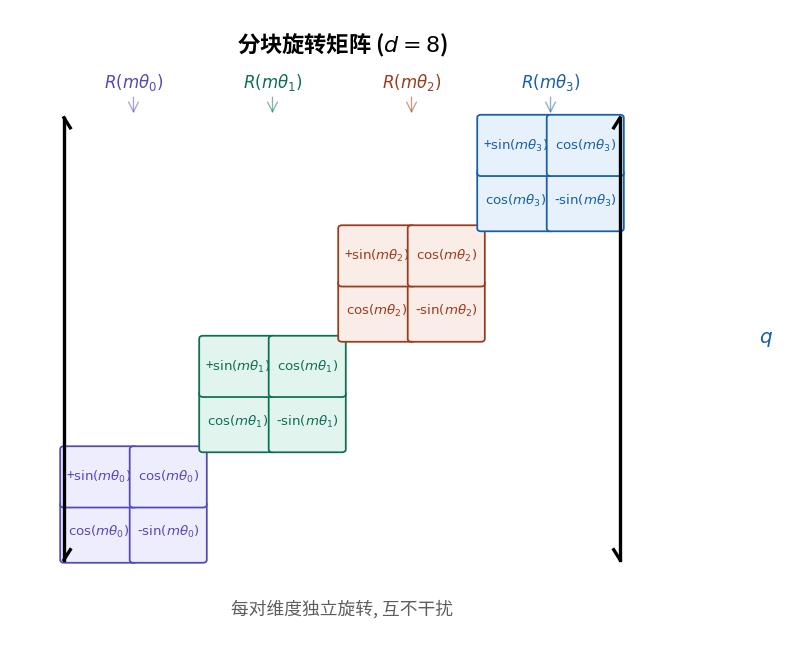
图中展示了 8 维向量被分成 4 对, 每对用不同的频率独立旋转, 整体构成块对角矩阵.
6. 高维验证小结#
上面的推导已经证明: 高维内积可以分解为:
⟨fq(q,m),fk(k,n)⟩=∑i=0d/2−1⟨q(i),R((n−m)θi)k(i)⟩
其中 q(i)=(q2i,q2i+1) 是第 i 个子空间的 2 维向量. 每个子空间的结果都只依赖于 m−n, 所以总和也只依赖 m−n.
这就是 RoPE 在高维下的完整形式.
7. 长距离衰减#
前面我们从目标出发推导了 RoPE 的形式. 现在来看 RoPE 自带的一个优雅性质: 长距离衰减.
假设 q 和 k 是来自同一分布的随机向量, 各分量均值为 0, 方差为 1, 且不同分量之间相互独立. 这意味着我们希望相关系数: 当 j=l 时 E[qjkl]=1, 当 j=l 时 E[qjkl]=0. 用 Kronecker delta 符号 δjl 统一表示就是 E[qjkl]=δjl (即 j=l 时为 1, 否则为 0).
δjl 是 Kronecker delta: δjl=1 当 j=l, 否则 δjl=0.
现在计算 RoPE 编码后内积的期望:
E[⟨fq(q,m),fk(k,n)⟩]=Ei=0∑d/2−1⟨R(mθi)q(i),R(nθi)k(i)⟩=i=0∑d/2−1E[⟨R(mθi)q(i),R(nθi)k(i)⟩]展开每个子空间的内积:
⟨R(mθi)q(i),R(nθi)k(i)⟩=(q2icosmθi−q2i+1sinmθi)(k2icosnθi−k2i+1sinnθi)+(q2isinmθi+q2i+1cosmθi)(k2isinnθi+k2i+1cosnθi)展开后有四项含 q2ik2i, 四项含 q2i+1k2i+1, 以及交叉项 q2ik2i+1 和 q2i+1k2i.
由于 q 和 k 的不同分量独立且均值为 0, 交叉项的期望为 0. 只有 q2ik2i 和 q2i+1k2i+1 的期望为 1:
E[q2ik2i]×(cosmθicosnθi+sinmθisinnθi)+E[q2i+1k2i+1]×(sinmθisinnθi+cosmθicosnθi)=2cos((m−n)θi)其中用了三角恒等式 cosmθicosnθi+sinmθisinnθi=cos((m−n)θi).
所以每个子空间贡献 2cos((m−n)θi). 把所有 d/2 个子空间加起来:
E[⟨fq(q,m),fk(k,n)⟩]=2i=0∑d/2−1cos((m−n)θi)这个求和函数在 m−n 增大时会呈现震荡衰减的趋势——距离越远, 预期的注意力分数越低. 这符合我们在自然语言中的直觉:相邻词通常比远距离的词关联更紧密, 而且”带震荡”的性质意味着某些特定距离的 token 也能获得较强注意力, 这与现实中周期性短语(如每第 n 个词)的匹配模式一致.
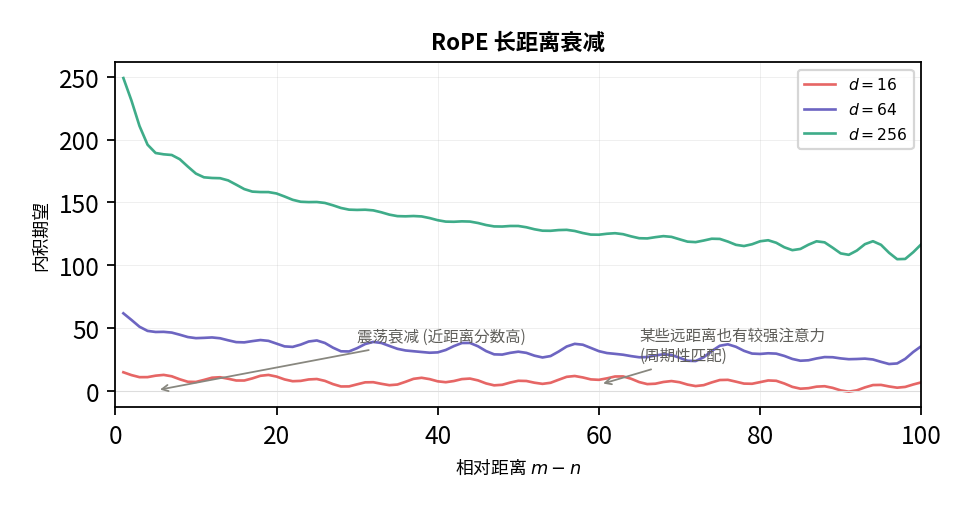
图中展示了不同维度下 RoPE 内积随距离的衰减趋势. 注意衰减不是单调的, 而是带有震荡的.
8. 30 行代码实现#
def precompute_rope_frequencies(dim: int, max_len: int, base: int = 10000):
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
positions = torch.arange(max_len).float()
angles = positions[:, None] * inv_freq[None, :] # (max_len, dim/2)
angles = torch.cat([angles, angles], dim=-1) # (max_len, dim)
return angles.cos(), angles.sin()
def apply_rope(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor):
# x: (batch, seq_len, head, dim)
# cos, sin: (seq_len, dim)
cos = cos[None, :, None, :] # (1, seq_len, 1, dim)
sin = sin[None, :, None, :] # (1, seq_len, 1, dim)
# 每对 (x_{2i}, x_{2i+1}) 交换并取反 = 旋转
x_rot = torch.stack([-x[..., 1::2], x[..., ::2]], dim=-1).reshape(x.shape)
return x * cos + x_rot * sin
使用:
cos, sin = precompute_rope_frequencies(dim=128, max_len=4096)
q_rotated = apply_rope(q, cos, sin)
k_rotated = apply_rope(k, cos, sin)
attn = torch.matmul(q_rotated, k_rotated.transpose(-2, -1))
9. 总结#
回头看整个推导过程, 最优雅的地方在于: 我们没有”发明”旋转矩阵, 而是从目标出发”发现”了它.
| 步骤 | 思路 | 数学形式 |
|---|
| ① 设定目标 | 内积只依赖相对位置 | ⟨fq(m),fk(n)⟩=g(m−n) |
| ② 尝试复数 | 2D 向量用复数表示 | q~=q1+iq2 |
| ③ 假设旋转 | 乘以单位复数编码位置 | q~m=q~⋅eimθ |
| ④ 验证目标 | 内积只含相对项 | Re[q~k~ˉei(m−n)θ] |
| ⑤ 回到实数 | 发现旋转矩阵 | R(mθ)=(cossin−sincos) |
| ⑥ 多频率 | 不同维度不同速度 | θi=10000−2i/d |
| ⑦ 高维扩展 | 块对角旋转矩阵 | 每对独立旋转 |
RoPE 现在已经是 LLaMA、Mistral、Gemma 等主流大模型的标配位置编码. 理解它的推导过程, 对理解后面长上下文扩展(PI、NTK、YaRN)也大有帮助.
参考资料#
- 苏剑林. (2021). “Transformer升级之路:2、博采众长的旋转式位置编码”. 科学空间 — 本文推导思路完全参考该文
- Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing 2022. arXiv:2104.09864
- Vaswani et al., Attention Is All You Need. NeurIPS 2017. arXiv:1706.03762